
Web crawling, or web data scraping, is an automated process where bots systematically browse the internet to collect data from websites. This process involves sending HTTP requests to web pages, downloading their content, and parsing the relevant information. Web crawlers, or spiders, are designed to navigate through websites by following hyperlinks and extracting data such as text, images, and links. This data can then be analyzed and used for various purposes, including search engine indexing, market research, competitive analysis, and content aggregation.
Web data scraping is essential for search engines like Google, which use crawlers to index web pages, making them searchable. Businesses leverage web crawling with Python to monitor competitors' pricing, gather market intelligence, and track consumer sentiment. Despite its advantages, ethical considerations and legal constraints must be observed to avoid violating website terms of service or privacy policies. Properly managed, web data scraping is a powerful tool for data-driven decision-making in various industries.
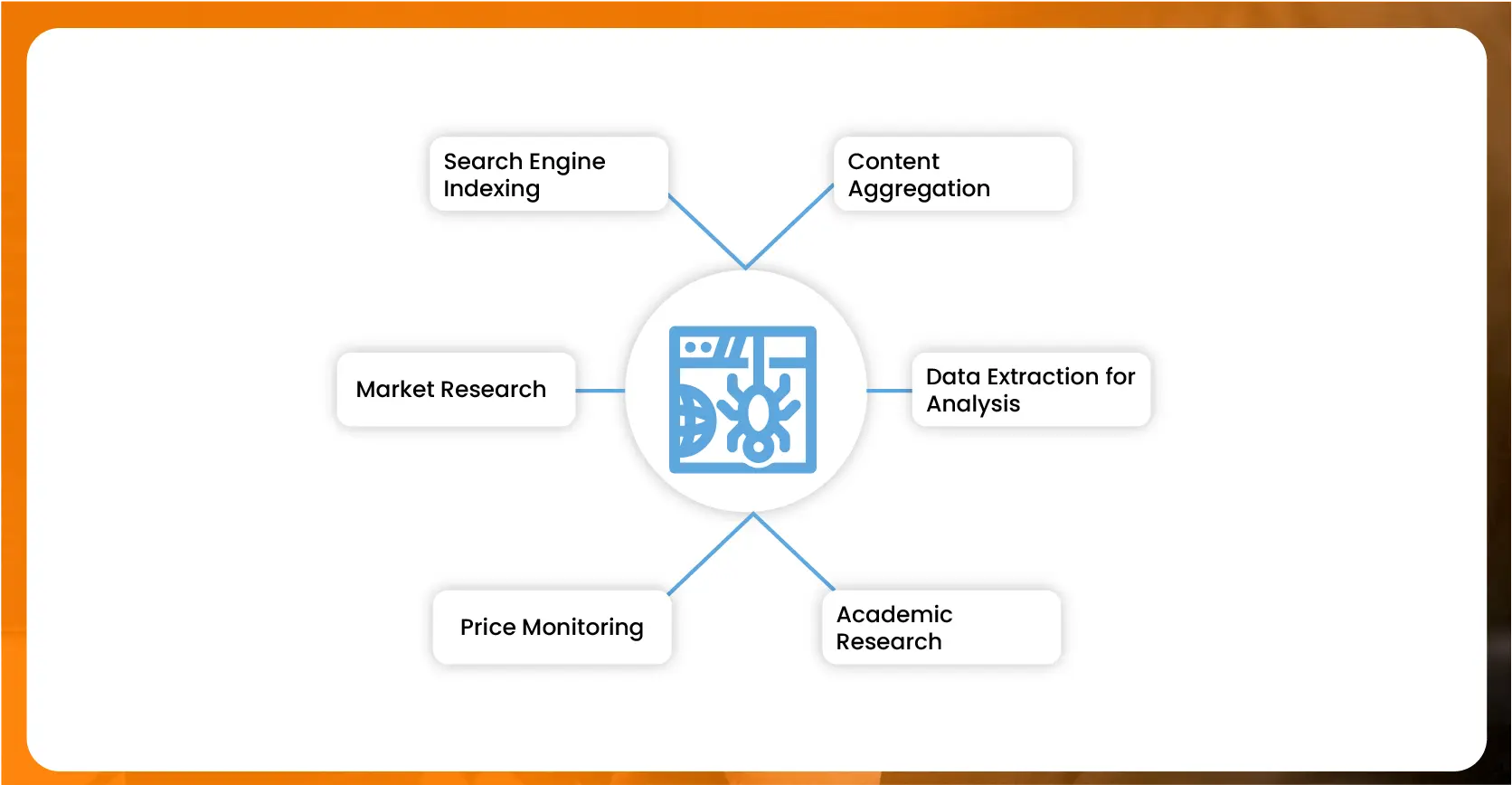
E-commerce website Crawling is essential for gathering and indexing vast amounts of online data. It enables search engine functionality, market research, competitive analysis, and informed decision-making across various industries.
Search Engine Indexing: Web Crawling E-commerce data is vital for search engines like Google, Bing, and Yahoo. Crawlers systematically browse the internet to index web pages, making them searchable. This allows users to find relevant information online quickly. Without web crawling, search engines wouldn't have a comprehensive index of the web, leading to poor search results and a less practical internet experience.
Market Research: Businesses use web crawling to gather data from competitors' websites, online forums, and social media platforms. This data extraction process provides valuable insights into market trends, consumer preferences, and emerging opportunities. By analyzing this information, companies can make informed decisions, develop better products, and create targeted marketing strategies.
Price Monitoring: Retailers and e-commerce platforms leverage Web Crawling Food Data to monitor competitors' prices. Businesses can adjust their pricing strategies to stay competitive by regularly scraping data from competitors' websites. This ensures they can offer attractive prices to customers while maintaining profitability.
Content Aggregation: Web crawling is used to aggregate content from multiple sources. News websites, for instance, use crawlers to gather articles from various publications, providing readers with a centralized platform for news consumption. Similarly, travel websites aggregate flight, hotel, and car rental information, making it easier for users to compare options and make bookings.
Data Extraction for Analysis: It is essential for extracting large volumes of data from various websites. This data can be used for analytics, machine learning models, and business intelligence. For instance, sentiment analysis tools use crawled data from social media to gauge public opinion on products or political events. This helps businesses and organizations understand public sentiment and react accordingly.
Academic Research: Researchers use web crawling to collect data on social sciences, economics, and public health studies. Researchers can analyze trends, behavior patterns, and public opinion by gathering data from online surveys, forums, and academic publications. This aids in producing evidence-based research and policy recommendations.

Web crawlers, or spiders, are essential tools for indexing and retrieving web content, serving diverse purposes from general search to specialized data gathering.
Purpose: These are the most common types of crawlers used by search engines like Google, Bing, and Yahoo to index web pages.
Functionality: They traverse the web by following links from one page to another, indexing the content they find.
Purpose: These crawlers are designed to gather information on a specific topic or from specific websites.
Functionality: They prioritize certain web pages based on predefined criteria or relevance to the target topic.
Purpose: These crawlers focus on updating previously indexed content.
Functionality: Instead of repeatedly crawling the entire web, they revisit and update only the pages that have changed since the last crawl.
Purpose: These crawlers aim to access and index content not typically reachable through standard web crawling, such as content behind login forms or in databases.
Functionality: They use techniques to interact with web forms and access hidden content.
Purpose: These crawlers are designed to work in a distributed manner to handle large-scale crawling tasks efficiently.
Functionality: They distribute the crawling workload across multiple machines or nodes, enabling faster and more efficient crawling of large datasets.
Purpose: These crawlers specialize in an industry or vertical, such as e-commerce, real estate, or job listings.
Functionality: They gather and index information from websites within the targeted industry, often focusing on specific data types like product listings, property details, or job postings.
Each type of crawler serves a unique purpose and is designed to handle specific challenges associated with web data extraction.

Web Crawling Grocery Data using Python typically involves several key steps:
Importing Necessary Libraries: Start by importing libraries like requests for fetching web pages and BeautifulSoup or Scrapy for parsing HTML content.
Sending HTTP Requests: Use requests to send HTTP GET requests to URLs you want to crawl, ensuring you handle exceptions and status codes appropriately.
Fetching Web Pages: Retrieve the HTML content of the web page from the response object returned by requests.
Parsing HTML Content: Use BeautifulSoup or lxml to parse the HTML content, enabling easy navigation and data extraction from the page's DOM structure.
Extracting Data: Identify and extract specific data elements (like links, text, images) using CSS selectors, XPath, or other methods provided by the parsing library.
Storing Data: Store the extracted data in a structured format (e.g., CSV, JSON, database) for further analysis or use.
Handling Pagination and Links: Implement logic to handle pagination and follow links to crawl multiple pages or sections of a website.
Respecting Robots.txt: Adhere to the website guidelines in the robots.txt file to ensure ethical crawling practices and avoid being blocked.
Handling Errors and Exceptions: Implement error handling to gracefully manage issues like timeouts, network errors, or unexpected HTML structures.
Throttling and Politeness: Implement throttling mechanisms to control the rate of requests sent to a website, respecting server load and avoiding IP bans.
Monitoring and Logging: Set up logging to track the crawling process, monitor for errors, and ensure the crawler operates smoothly over time.
Testing and Debugging: Test the crawler on different websites and scenarios, debugging any issues with the parsing or data extraction logic.
Python's versatility and powerful libraries make it popular for web crawling tasks. It offers robust solutions for both simple and complex scraping requirements.
Conclusion: Web Crawling Travel Data offers a robust solution for efficiently extracting and analyzing web data. By leveraging libraries like requests, BeautifulSoup, and Scrapy, Python facilitates seamless HTTP requests, HTML parsing, and data extraction from diverse web sources. Implementing proper handling of pagination, links, and robots.txt ensures adherence to web crawling ethics and legalities. Error handling and logging mechanisms enhance reliability while throttling controls maintain server politeness. Python's flexibility allows for customization and scalability in crawling tasks. It is ideal for beginners and advanced users tackling various scraping challenges across domains like e-commerce, research, and data science.
Discover unparalleled web scraping service or mobile app data scraping offered by iWeb Data Scraping. Our expert team specializes in diverse data sets, including retail store locations data scraping and more. Reach out to us today to explore how we can tailor our services to meet your project requirements, ensuring optimal efficiency and reliability for your data needs.