
Web scraping is a powerful technique for collecting data from websites, particularly useful for gathering information on Tim Hortons stores across Canada. This fast-food restaurant chain, a beloved Canadian coffee icon, has thousands of locations nationwide. Scraping Tim Hortons store data across Canada can provide valuable insights for market analysis, competitor research, or personal projects. Restaurant data scraping allows you to collect addresses, operating hours, and contact information efficiently. Scrape Restaurant Location Data in Canada to help businesses understand market trends, optimize operations, and identify potential areas for expansion. Using web scraping techniques, you can systematically gather comprehensive data on Tim Hortons stores, offering a competitive edge in the fast-food industry. This approach saves time and resources and ensures accuracy and completeness, enabling better decision-making and strategic planning. With the right tools and methods, you can Scrape Tim Hortons locations and the data availed can be a game-changer for businesses and researchers.

Data scraping from Tim Hortons stores can uncover valuable information for various purposes. Here are detailed points on what Tim Hortons data scraping services can reveal:
Restaurant Location Data Scraping involves several steps. It includes setting up the environment, fetching webpage content, parsing HTML, identifying and extracting data, handling JavaScript-rendered content, and implementing rate limiting and error handling.
Identify the Target URL: The target URL is likely their store locator page for Tim Hortons stores. This page usually lists all store locations, addresses, and sometimes additional details like operating hours and contact information.
Inspect the Page: Use browser developer tools (usually accessible via F12) to inspect the page structure and Scrape Restaurant Data. Identify the HTML elements that contain the desired data.
Choose the Right Tools: Python is a popular language due to its simplicity and the availability of powerful libraries like BeautifulSoup, Scrapy, and Selenium.
Install the necessary Python libraries:
pip install requests
pip install beautifulsoup4
pip install pandas
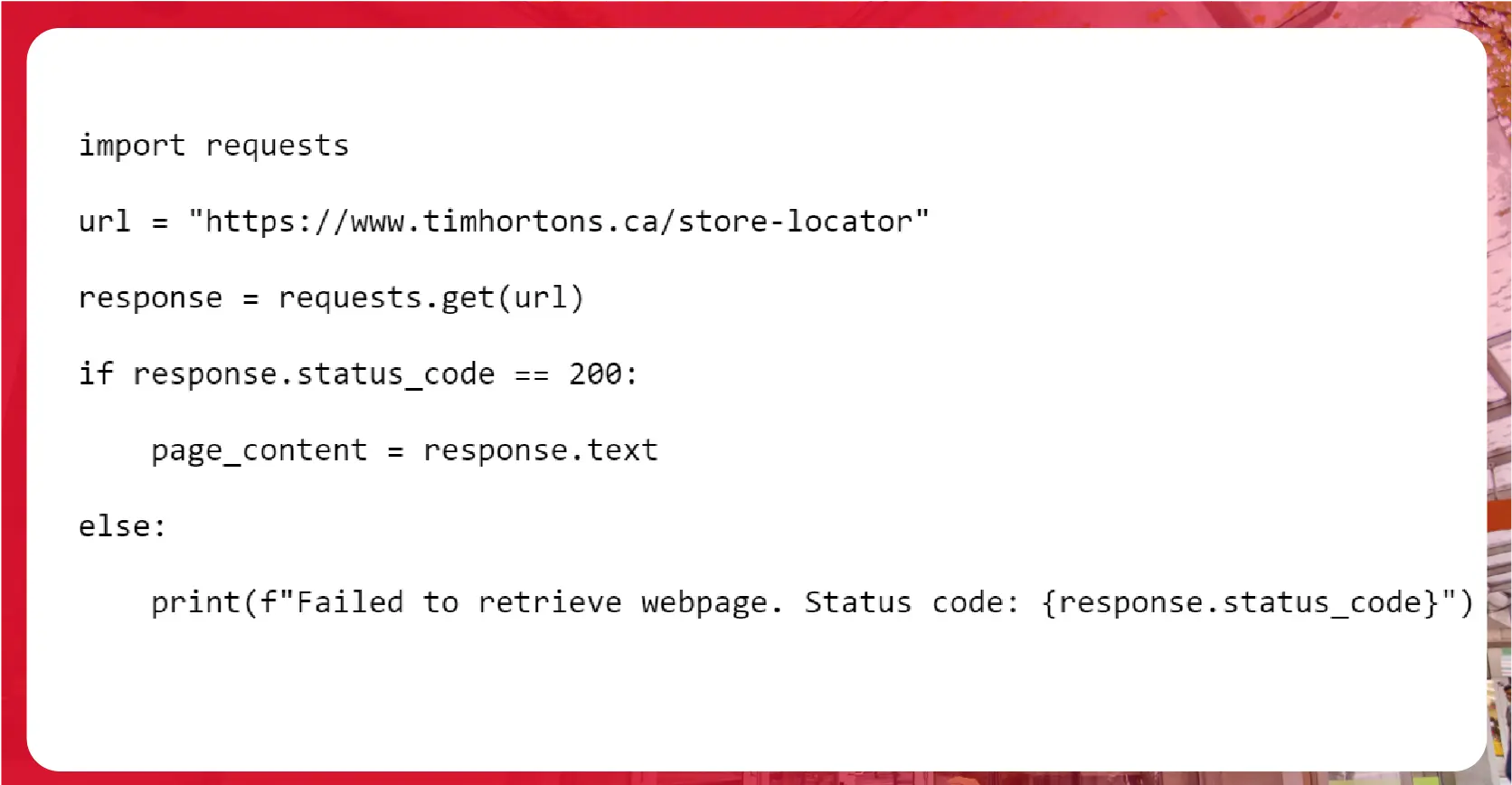
Use the requests library to fetch the webpage content.
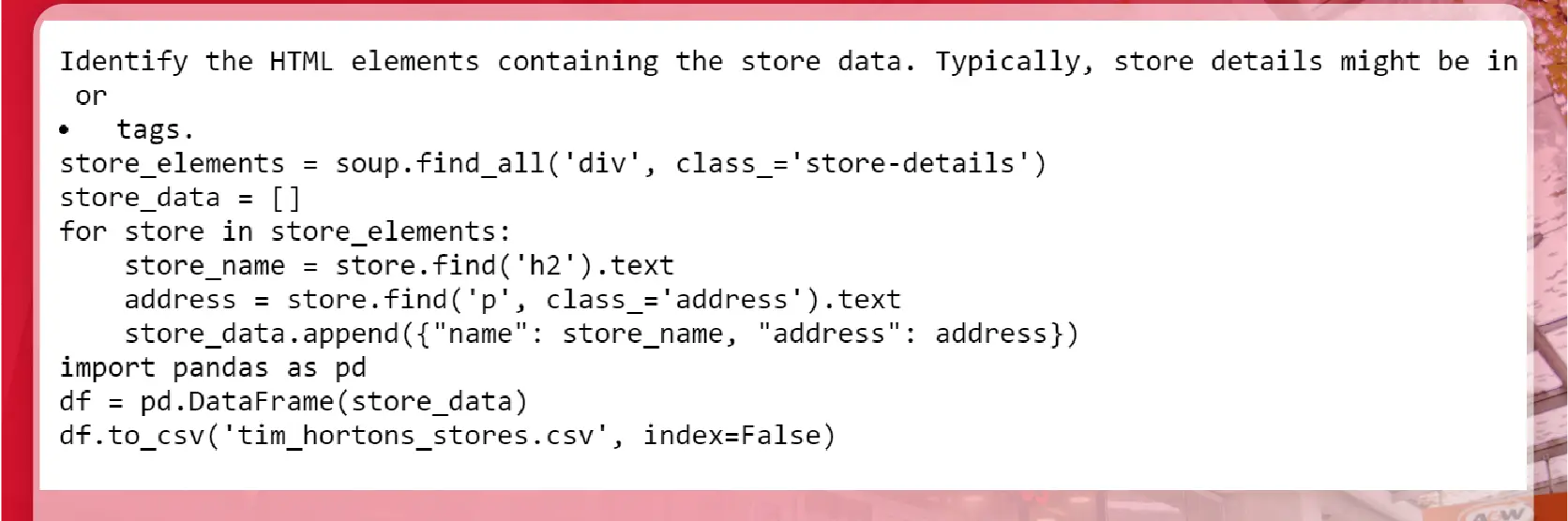
Use BeautifulSoup to parse the HTML content.

Identify the HTML elements containing the Tim Hortons store database Canada. Typically, store details might be in < div > or < li > tags.
Some websites use JavaScript to render content dynamically. In such cases, more than requests and BeautifulSoup are required. Use Selenium, a browser automation tool, to handle JavaScript-rendered pages.

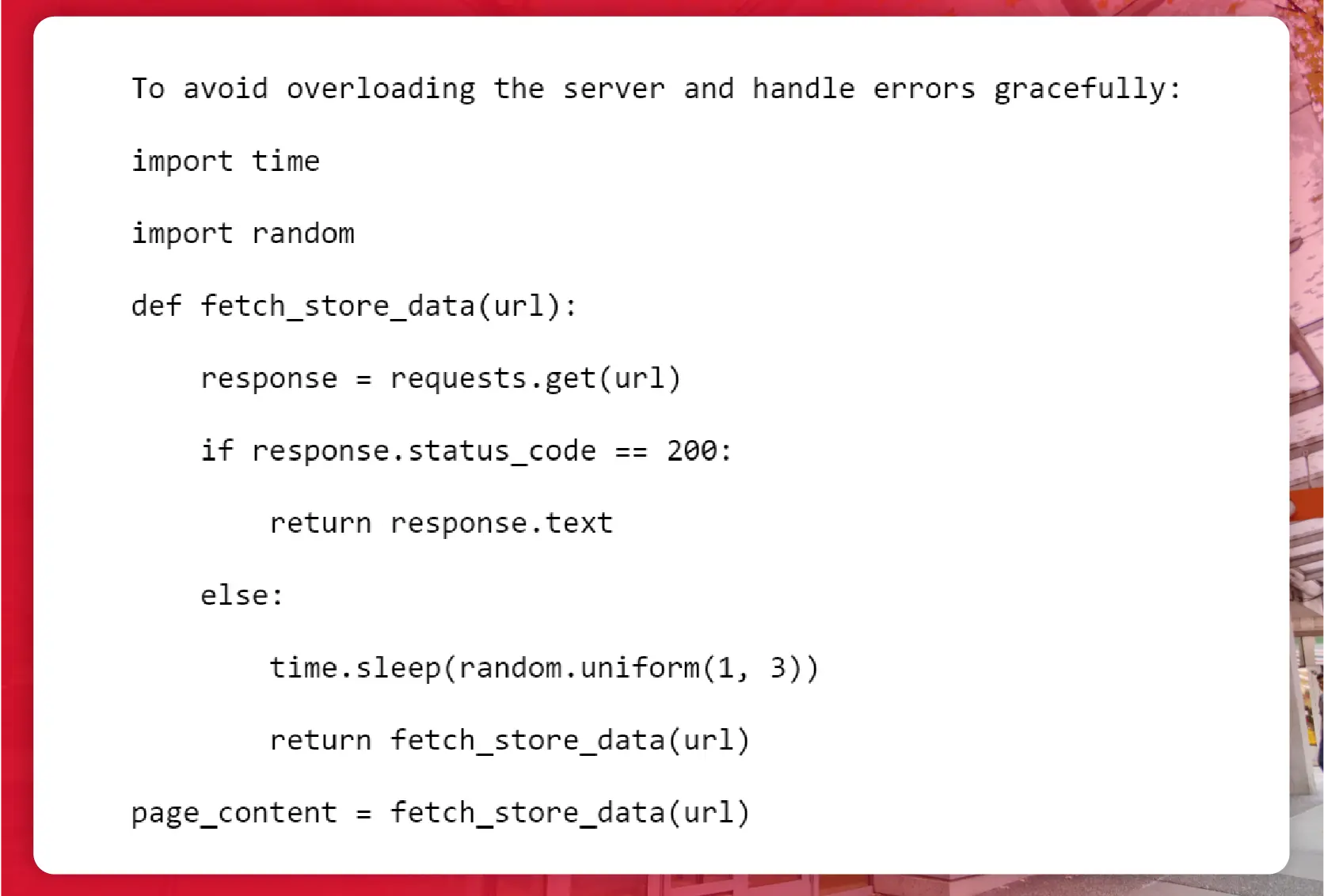
To avoid overloading the server and handle errors gracefully:
Conclusion: Restaurant data scraper can be a valuable tool for gathering data from Tim Hortons stores across Canada. It provides valuable insights for market analysis, competitor research, and personal projects. Following best practices and adhering to legal and ethical guidelines, you can efficiently collect comprehensive information such as store locations, operating hours, contact details, and customer reviews. Utilizing tools like BeautifulSoup and Selenium allows for handling static and dynamic web content, ensuring accurate and thorough data extraction. This systematic approach using restaurant data scraping services saves time and resources. It empowers businesses and researchers with actionable insights, driving informed decision-making and strategic planning in the fast-food industry.
Discover unparalleled web scraping service or mobile app data scraping offered by iWeb Data Scraping. Our expert team specializes in diverse data sets, including retail store locations data scraping and more. Reach out to us today to explore how we can tailor our services to meet your project requirements, ensuring optimal efficiency and reliability for your data needs.