Social publishing platforms have become rich sources of data for various analytical purposes. Scraping data from social publishing platforms is the process of collecting information from websites and is increasingly used to gather insights from platforms like Medium. This trend is driven by the need to analyze user behavior, content popularity, and sentiment analysis to inform marketing strategies, product development, and academic research.
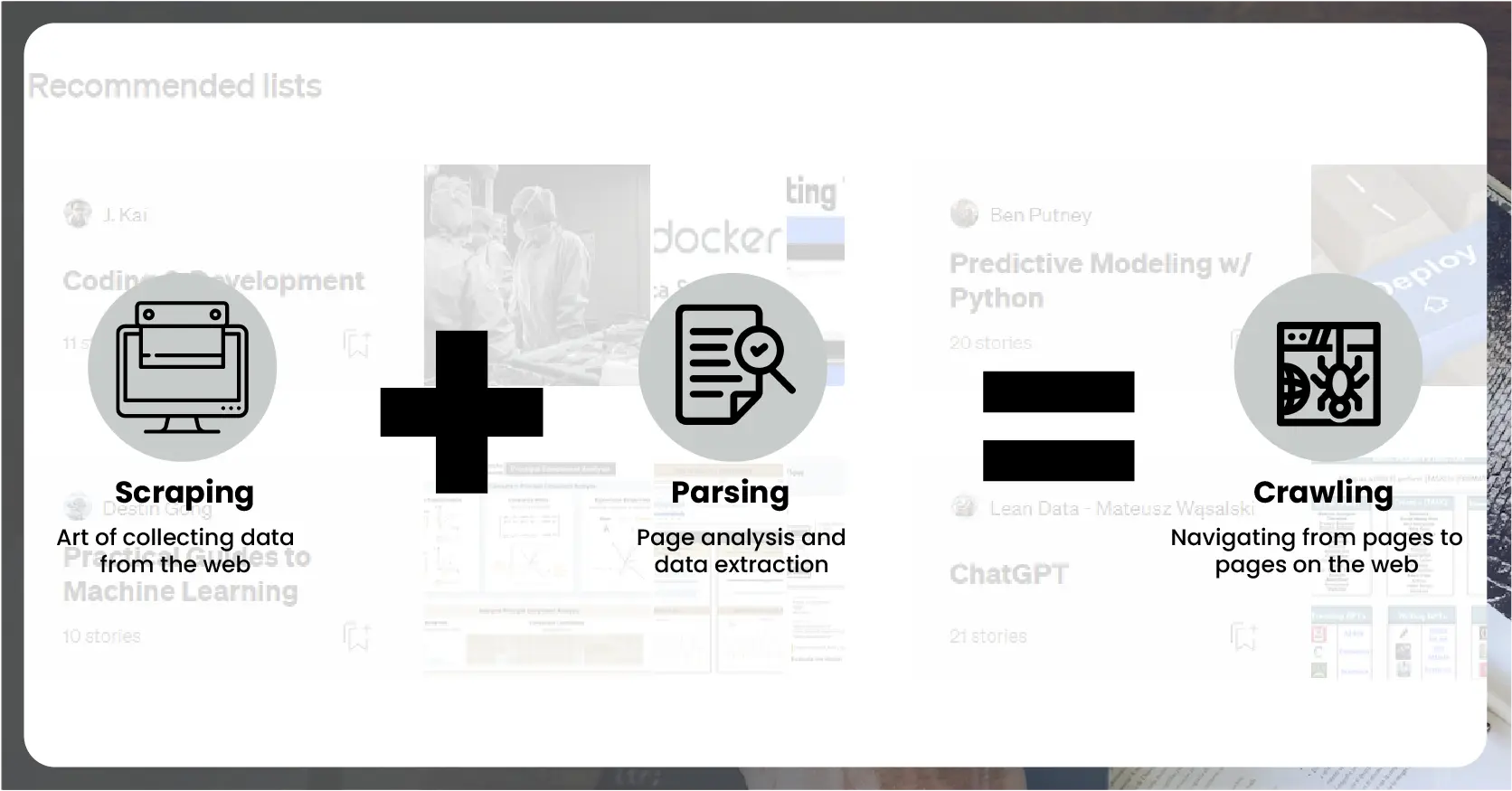
Medium, a popular social publishing platform, hosts a diverse range of articles on numerous topics, making it an invaluable resource for data analysts and researchers. Thus, Scraping Medium data using Python involves libraries such as BeautifulSoup and Scrapy to navigate the HTML structure of Medium's web pages and extract relevant information. By automating this process, analysts can efficiently collect large volumes of data, allowing for comprehensive analysis and a better understanding of content trends and audience engagement on Medium.
Scraping Medium data can yield a wealth of information that can be valuable for various purposes. Here are some key insights you can obtain:
Titles and Summaries: Extracting article titles and summaries helps understand the discussed main topics.
Full Text: Access to the complete text of articles allows for in-depth content analysis and text mining.
Trends Over Time: Analyzing publication dates can reveal trends in content creation and peak posting times.
Author Information: Collecting author details such as bios and follower counts using Medium data scraping services can help identify influential writers and thought leaders.
Author Activity: Understanding an author's posting frequency and engagement can provide insights into their influence and reach.
Popular Tags: Identifying frequently used tags can highlight trending topics and areas of interest.
Topic Analysis: Detailed analysis of tags can inform content strategy and niche identification.
Claps and Responses: Engagement metrics such as claps, comments, and shares indicate how well an article resonates with readers.
Reading Time and Views: Understanding reader interaction and article reach helps assess content impact
Follower Counts: Collecting follower data helps gauge the popularity and influence of authors and publications.
Publication Details: Information on specific Medium publications can aid in competitive analysis and collaboration opportunities.
Reader Sentiment: Analyzing comments and article content for sentiment provides insights into reader perceptions and opinions.
Trend Analysis: Sentiment trends can indicate public mood and reactions over time.
Cross-Posting: Identifying articles shared across multiple platforms can reveal content distribution strategies.
Reach and Impact: Understanding how content spreads can help measure its broader impact.
Python libraries such as BeautifulSoup, Scrapy, and Selenium can efficiently extract these data points from Medium. This information can be leveraged for market research, content strategy, academic studies, and more, offering valuable insights into the dynamics of digital publishing and audience engagement.
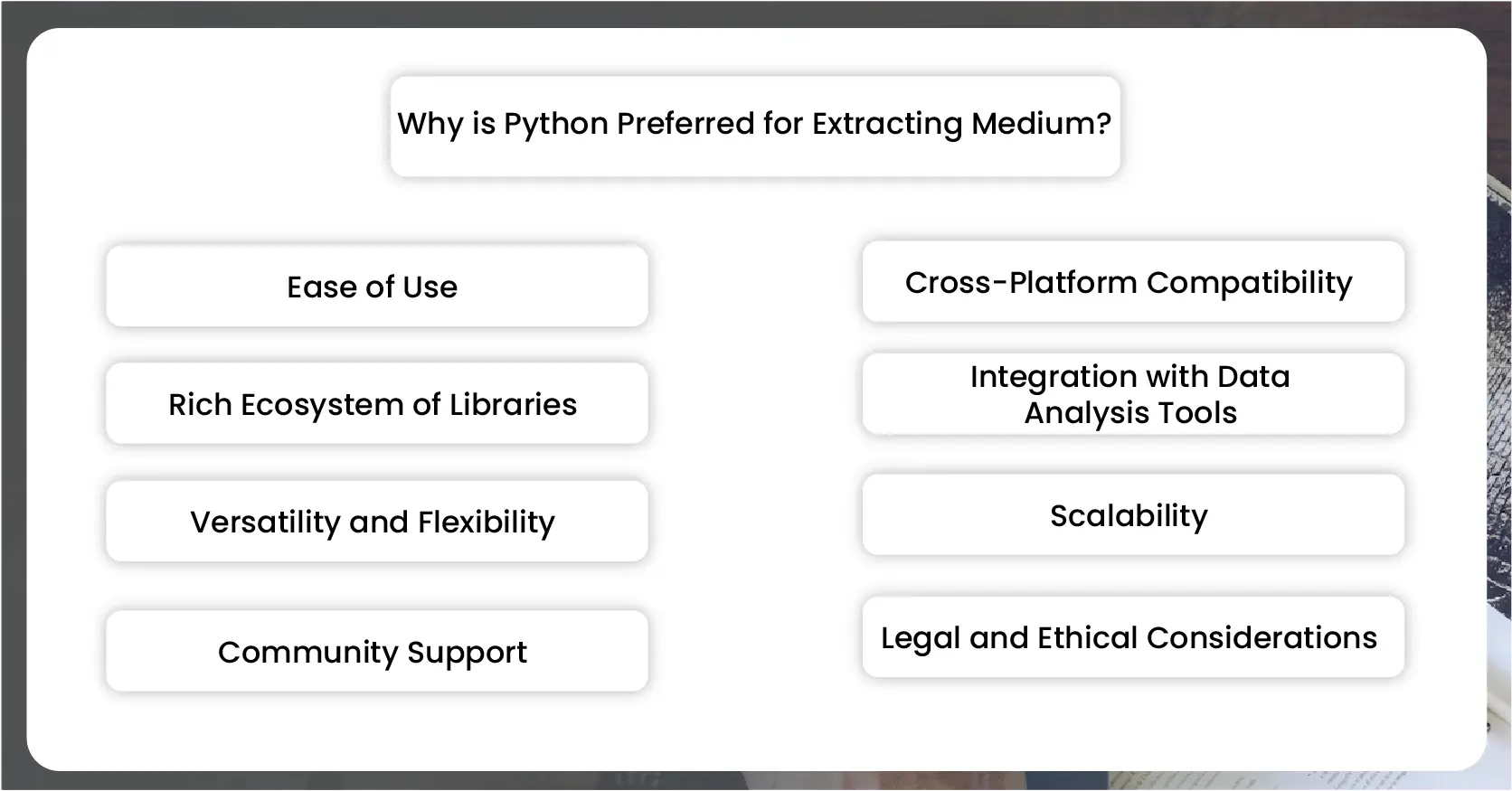
Python is preferred for extracting data from Medium and similar platforms due to several key reasons:
Python's syntax is clear and readable, making it accessible for beginners and experienced programmers. This ease of use reduces development time and allows data extraction scripts to be written quickly and efficiently.
Python boasts a vast ecosystem of libraries and tools specifically designed for web scraping and data extraction. Libraries like BeautifulSoup, Scrapy, and Selenium simplify navigating HTML structures, handling dynamic content, and interacting with web pages, which are essential for scraping data from Medium.
Python is a versatile language capable of handling various tasks, from simple scripts to complex data analysis pipelines. Its flexibility allows developers to seamlessly integrate data scraping into larger data processing workflows.
Python has a large and active community of developers and enthusiasts who contribute to its libraries and provide support through forums, documentation, and tutorials. This community support ensures that solutions and best practices are readily available for any challenges encountered during the scraping process.
Python is cross-platform, meaning scripts developed on one operating system (e.g., Windows, macOS, Linux) can run on others with minimal modifications. This compatibility ensures that data scraping projects can be deployed across different environments without issues.
Python integrates well with popular data analysis and machine learning libraries such as pandas, numpy, and sci-kit-learn. This integration allows scraped data to be seamlessly analyzed, visualized and used to build predictive models, providing deeper insights from Medium data.
Python's scalability makes it suitable for handling large volumes of data efficiently. Whether scraping a few articles or thousands, Python's capabilities and libraries enable developers to scale their scraping efforts as needed.
Python's robustness and versatility also extend to handling legal and ethical considerations in web scraping. Developers can implement techniques such as rate limiting, respecting robots.txt files, and obtaining consent when necessary to ensure compliance with website terms of service and legal regulations.
Python's combination of simplicity, powerful libraries, community support, versatility, and compatibility makes it the preferred choice for extracting data from Medium and other web platforms. Its capabilities enable developers to gather and analyze data efficiently, driving insights and decision-making in various domains.
Scraping data from Medium using Python involves several steps, from setting up your environment to extracting and processing the data. Below are the detailed steps and example code snippets using BeautifulSoup, a popular Python library for parsing HTML and XML documents.
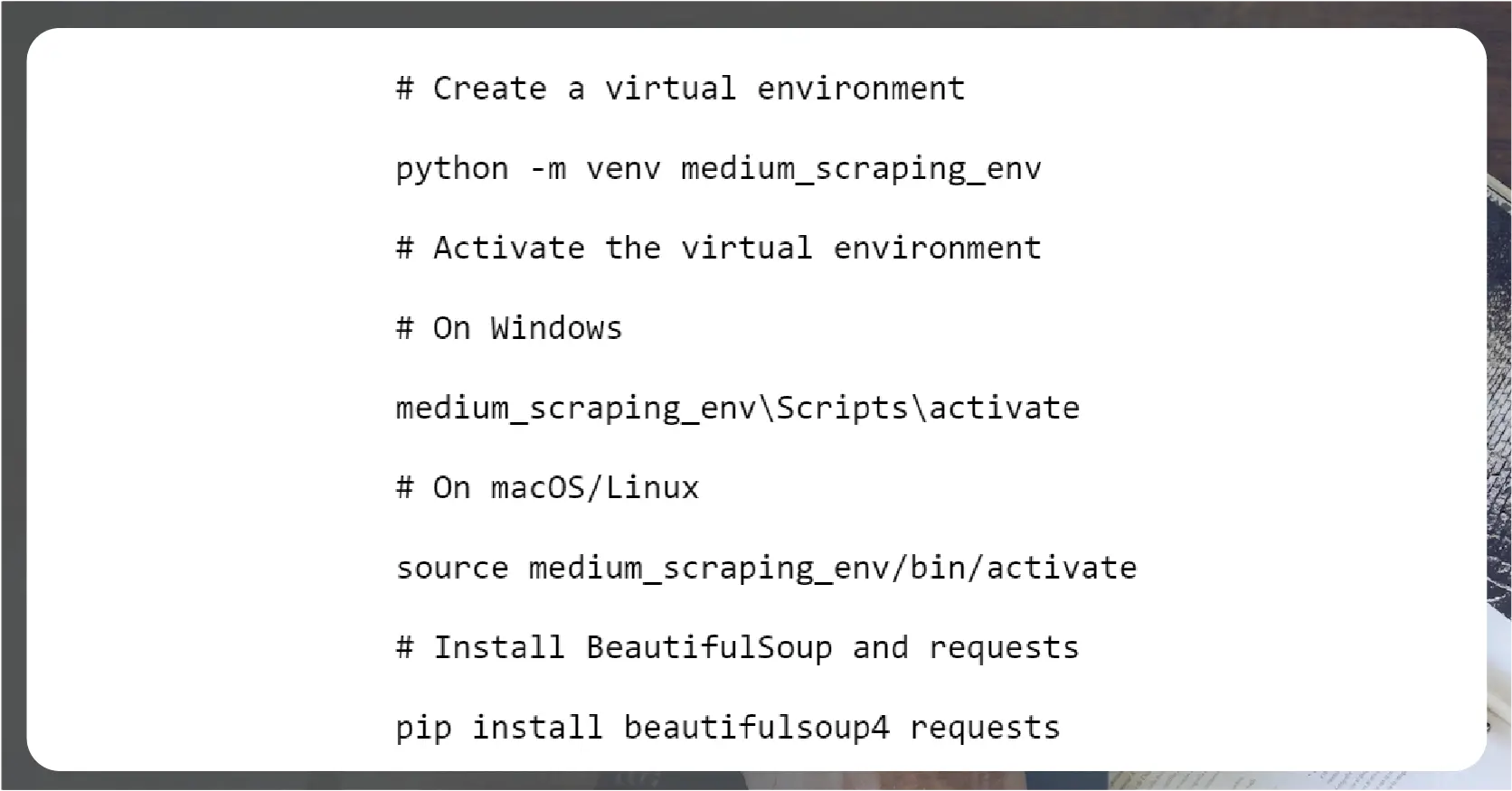
First, ensure you have Python installed. Create a virtual environment and install the necessary libraries:
Use browser developer tools to inspect the HTML structure of a Medium page. Identify the HTML elements that contain the data you want to scrape (e.g., article titles, authors, publication dates).
Create a Python script (scrape_medium.py) to fetch and scrape data from Medium. Here's a basic example using BeautifulSoup to scrape article titles and authors:

Execute your scraping script to fetch and print article titles and authors from Medium: python scrape_medium.py
Extend your script to process and store scraped data in a suitable format (e.g., CSV, JSON, database) for further analysis or use.
For collecting multiple pages or handling dynamically loaded content (e.g., infinite scroll), modify your script to navigate through pages or load content dynamically using techniques like scrolling down the page or clicking "Load More" buttons.
Implement error handling to manage exceptions (e.g., network errors, HTML structure changes). Respect Medium's robots.txt file and terms of service to ensure ethical scraping practices.
Test your script with a small dataset to accurately capture the desired information. Then, validate the scraped data against the original Medium pages to verify its correctness.
By following these steps and adapting the code as needed, you can effectively collect data from Medium using Python and BeautifulSoup, enabling you to gather valuable insights from articles and authors on the platform.
Conclusion: Leveraging Python as a Medium data scraper offers profound insights into content trends, user engagement, and author dynamics on the platform. By utilizing tools like BeautifulSoup and Scrapy, analysts can efficiently extract and analyze article titles, authors, publication dates, and engagement metrics. This process enhances understanding of audience preferences and sentiment and supports informed marketing, content strategy, and academic research decision-making. As data-driven approaches continue to shape digital landscapes, mastering Medium data scraping with Python remains crucial for extracting actionable intelligence and staying competitive in content-driven domains.
Discover unparalleled web scraping service or mobile app data scraping offered by iWeb Data Scraping. Our expert team specializes in diverse data sets, including retail store locations data scraping and more. Reach out to us today to explore how we can tailor our services to meet your project requirements, ensuring optimal efficiency and reliability for your data needs.