
In today's data-driven world, Web Scraping with AWS Lambda has become crucial for businesses, researchers, and developers to extract valuable information from websites. With the rapid growth of e-commerce, real-time data collection, and online research, the ability to scale web scraping processes has become essential. Traditional methods of scraping data from websites can often be resource-intensive and difficult to scale, especially when the data needs to be extracted regularly from numerous sites. This is where cloud computing solutions like Real-Time Web Scraping with AWS Lambda come in.
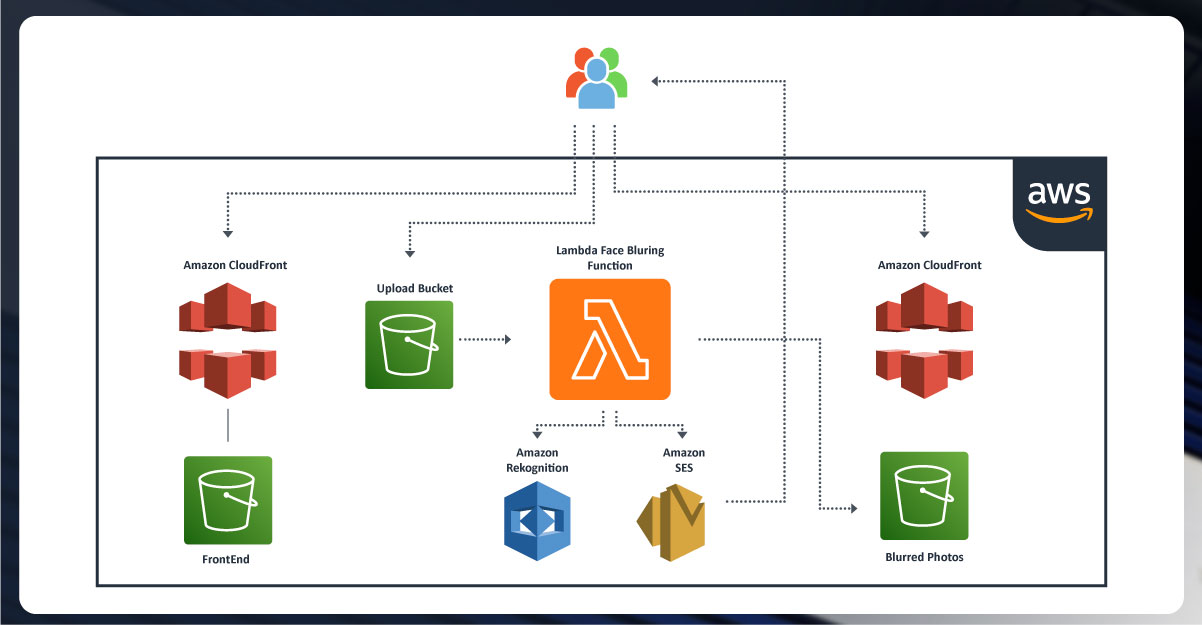
Amazon Web Services (AWS) Lambda is a serverless computing service that run code without provisioning or handling servers. Lambda automatically balances your applications by running code in response to events, and it supports various programming languages, including Python, JavaScript (Node.js), and Java. The serverless nature of AWS Lambda means you only pay for the compute time you use, which can significantly reduce costs, especially for tasks like web scraping that require handling multiple requests at scale.
With AWS Lambda Ecommerce Price Tracker, you can build scalable applications that automatically adapt to the load, scaling up or down based on the demand without the need to manage servers or infrastructure. This makes AWS Lambda a perfect solution for scalable web scraping projects.
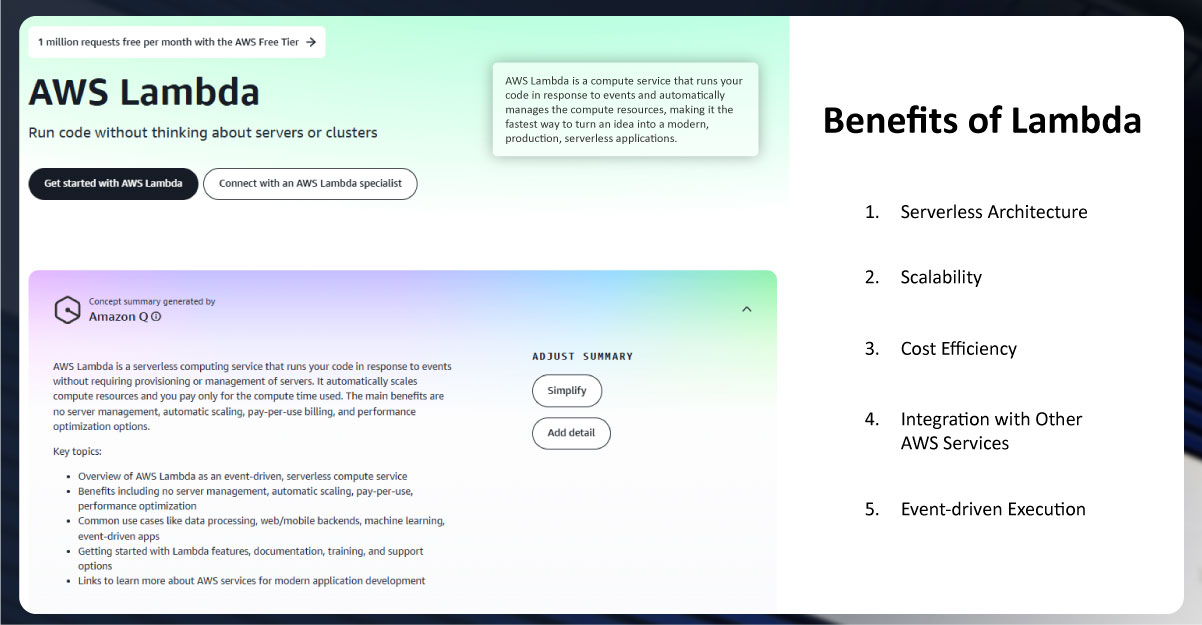
Before diving into the implementation details, it's essential to understand why AWS Lambda is an excellent choice for scalable web scraping:
1. Serverless Architecture: Web Scraping APIs with AWS Lambda eliminate the need to manage infrastructure. You write the scraping code and upload it to Lambda, and AWS handles the rest—scaling and managing the resources based on the incoming requests.
2. Scalability: Data Collection with AWS Lambda automatically scales up to handle many scraping tasks concurrently and scales down when the demand decreases. Whether you are scraping a few pages or thousands, Lambda adjusts accordingly.
3. Cost Efficiency: Ecommerce Data Scraping with AWS Lambda follows a pay-per-use model, meaning you only pay for the compute time you use. There are no ongoing costs for idle servers, which can be a significant advantage for scalable scraping projects.
4. Integration with Other AWS Services: Lambda integrates seamlessly with other AWS services like Amazon S3 (for storing scraped data), AWS DynamoDB (for storing results in a database), and AWS CloudWatch (for monitoring and logging). This creates a robust ecosystem for AWS Lambda for Ecommerce Inventory Tracking applications.
5. Event-driven Execution: Lambda can be triggered by various events, such as HTTP requests via API Gateway, changes in data in Amazon S3, scheduled executions using Amazon CloudWatch Events, and more. This makes it perfect for automating scraping tasks.
Now that we've discussed why AWS Lambda is an excellent choice for web scraping let's walk through the process of building a scalable web scraping solution.
Step 1: Set Up AWS Lambda
To use AWS Lambda, you must set up an AWS account (if you still need to do so). Once your account is ready, follow these steps:
1. Create a Lambda Function:
2. Set Up IAM Role for Permissions:
3. Upload or Code Your Scraping Script:
Step 2: Write the Scraping Script
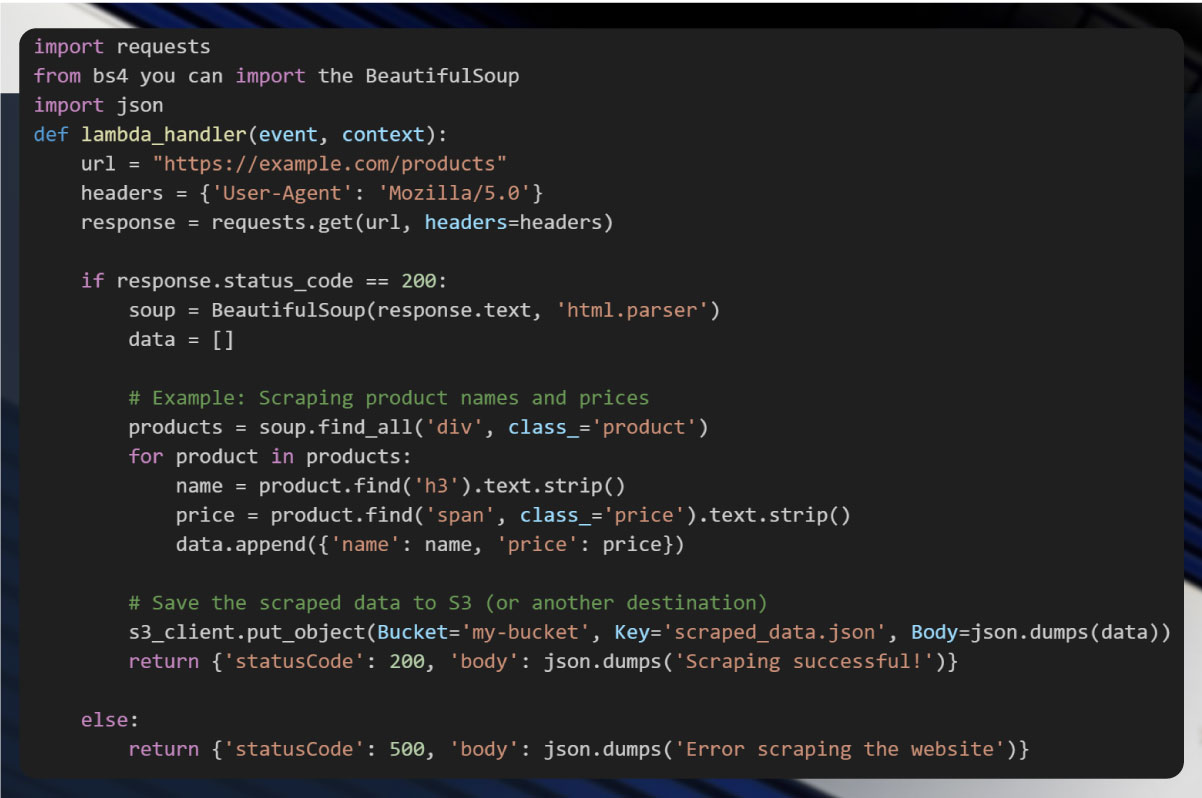
Let's assume you're using Python for web scraping. Here's a basic outline of how to write a Lambda function to scrape a website.
In this example:
Step 3: Trigger Lambda with CloudWatch Events
AWS Lambda can be triggered in several ways. One helpful method for scraping tasks is to set up scheduled triggers using Amazon CloudWatch Events.
1. Create a CloudWatch Rule:
2. Configure the Rule:
Step 4: Handle Large Scale Scraping

While AWS Lambda is scalable by default, there are some things you can do to optimize your web scraping process to handle larger-scale scraping projects:
1. Parallelize Scraping Tasks:
2. Use Amazon S3 for Storing Data:
3. Use AWS DynamoDB for Storing Scraped Data:
4. Handle CAPTCHA and Anti-bot Mechanisms:
Step 5: Monitor and Optimize
1. Monitoring with AWS CloudWatch:
2. Optimize Lambda Performance:
3. Error Handling:
Using AWS Lambda for scalable web scraping is an efficient, cost-effective solution that allows businesses, developers, and researchers to perform Web Scraping Ecommerce Product Data at scale without worrying about server management or infrastructure. With its serverless architecture, automatic scaling, and deep integration with other AWS services, AWS Lambda is an ideal tool for handling large-scale web scraping projects. Following the steps outlined in this article, you can easily set up, automate, and optimize your Ecommerce Product Data Scraper tasks, making it easier to gather valuable data from the web for analysis, insights, and decision-making.
Experience top-notch web scraping service and mobile app scraping solutions with iWeb Data Scraping. Our skilled team excels in extracting various data sets, including retail store locations and beyond. Connect with us today to learn how our customized services can address your unique project needs, delivering the highest efficiency and dependability for all your data requirements.